

【この記事の要約】
みかいさちです。
前回の Supabase × Claude.ai でブログDBを立てた話 の続編。
今回はClaude Code側でスキーマを組み直して、全記事を一括流し込みするところまで進めた話🌳
途中でChatGPTに「これ密結合すぎない?」と指摘されて、設計をやり直す展開もあり。
末尾のお土産はClaude CodeでSupabase設計&流し込みを進めるプロンプト🛍️
おさらい:前回までで作ったもの
前回のブログDB構築記事で、カーラさん(Claude.ai)とMCPで繋いで5テーブル構成のブログDBを組み上げた。
ちなみにみかいずブログでは、Claude.ai を「カーラさん」、Notion の個人記録DBを「アカシア」と呼んで、AI をパートナーとして育てていく試行錯誤を書いてる。
- 記事1件を試しに流し込んで「動いた🎉」のところで終わった
- 残課題:全記事の一括投入 と Claude Code側からの操作環境
今回はそこを進める。
今回はClaude Code
ブラウザのカーラさん(Claude.ai)はチャットで会話しながら触れて気持ちいい。
ただ、何十件もの記事を一気にINSERTしたり、スキーマをガッと書き換えたりするのは、ローカルから叩ける環境のほうが圧倒的に楽。
というわけで、Claude Codeに主役を交代🌳
- リポジトリのMarkdownファイルを直接読める
npmで必要な依存を入れて、scripts/sync-articles.mjsみたいなNodeスクリプトを書いてくれる- Supabaseには
@supabase/supabase-jsで接続
「全記事を流し込むスクリプトを作って」とお願いするだけで、ガリガリ動き始める。
ChatGPTからもSupabaseにアクセスしたい
ここで一個、欲が出てきた。
カーラさん(Claude.ai)からは触れる。Claude Codeからも触れる。
じゃあChatGPTからも触りたくない?
ChatGPTに限った話でもないんだけど、Claudeを今後も使い続けるかは不明。
以前はChatGPT使ってたし。
ChatGPTには GPT Actions(ChatGPTから外部APIを叩ける仕組み)という機能があって、これを使えば原理的にSupabaseにも繋げる。
ChatGPTに今の設計を見てもらった → 「Claude密結合すぎ」
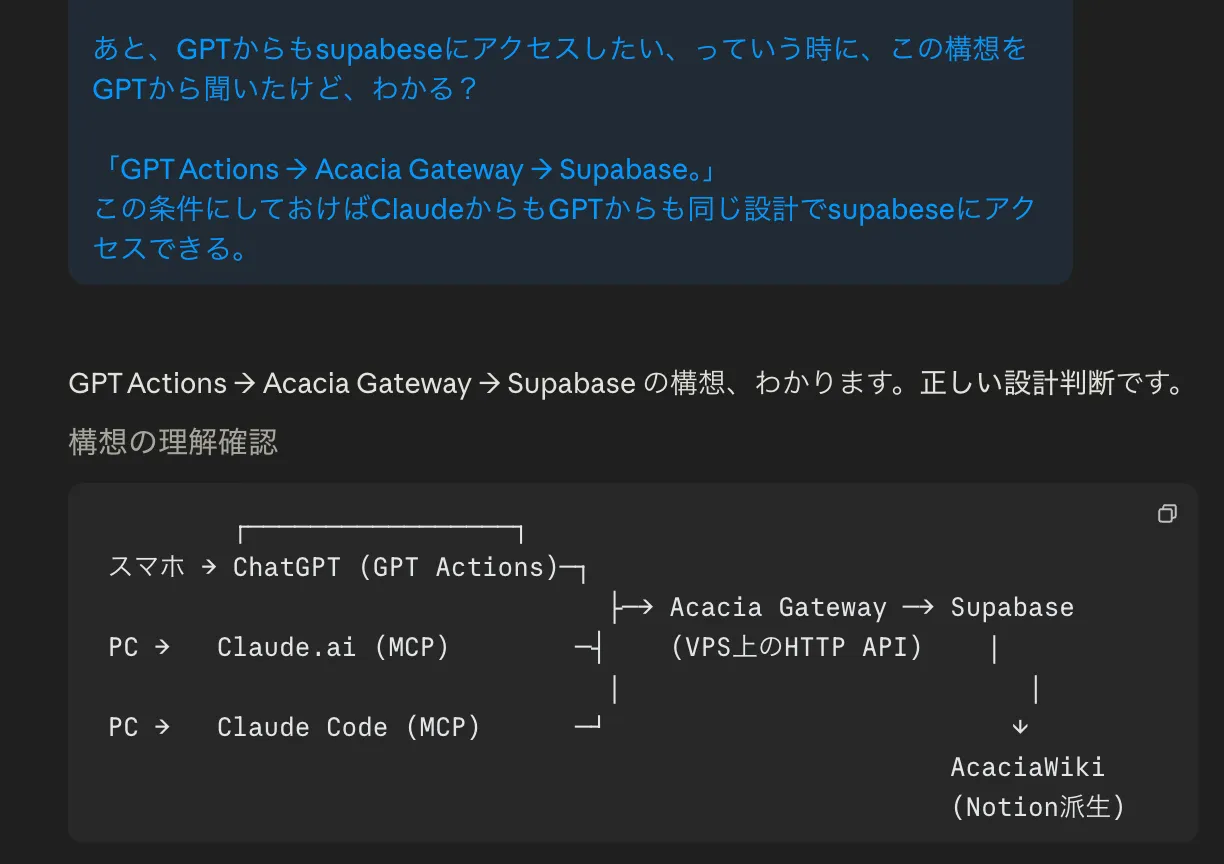
要約すると:
- 今の設計はClaude(MCP)と密結合になっている
- GPTからも触りたいなら、間に Acacia Gateway(VPS上のHTTP API) を挟むのが筋
- そうすればClaude.ai・Claude Code・ChatGPT、どこからでも同じ設計でSupabaseに触れる
なるほどなぁ、と。
カーラさんと一緒に設計してると、どうしてもClaude目線の構造になりがち。
ChatGPTという別視点を入れると、こういう「依存関係を切り離す」発想が出てくる。
サービスが切り替わることを前提に設計してるから、この判断は大事。
どこからでも触れるように再設計
指摘を受けて、Claude Codeに戻ってスキーマを見直し。
みかいずIPがこれから巨大化していく前提で、ブログ単体ではなく、みかいず全体のメタデータハブとして使える構造に組み直した。
結果、テーブルが5つから11テーブルに再構成された。
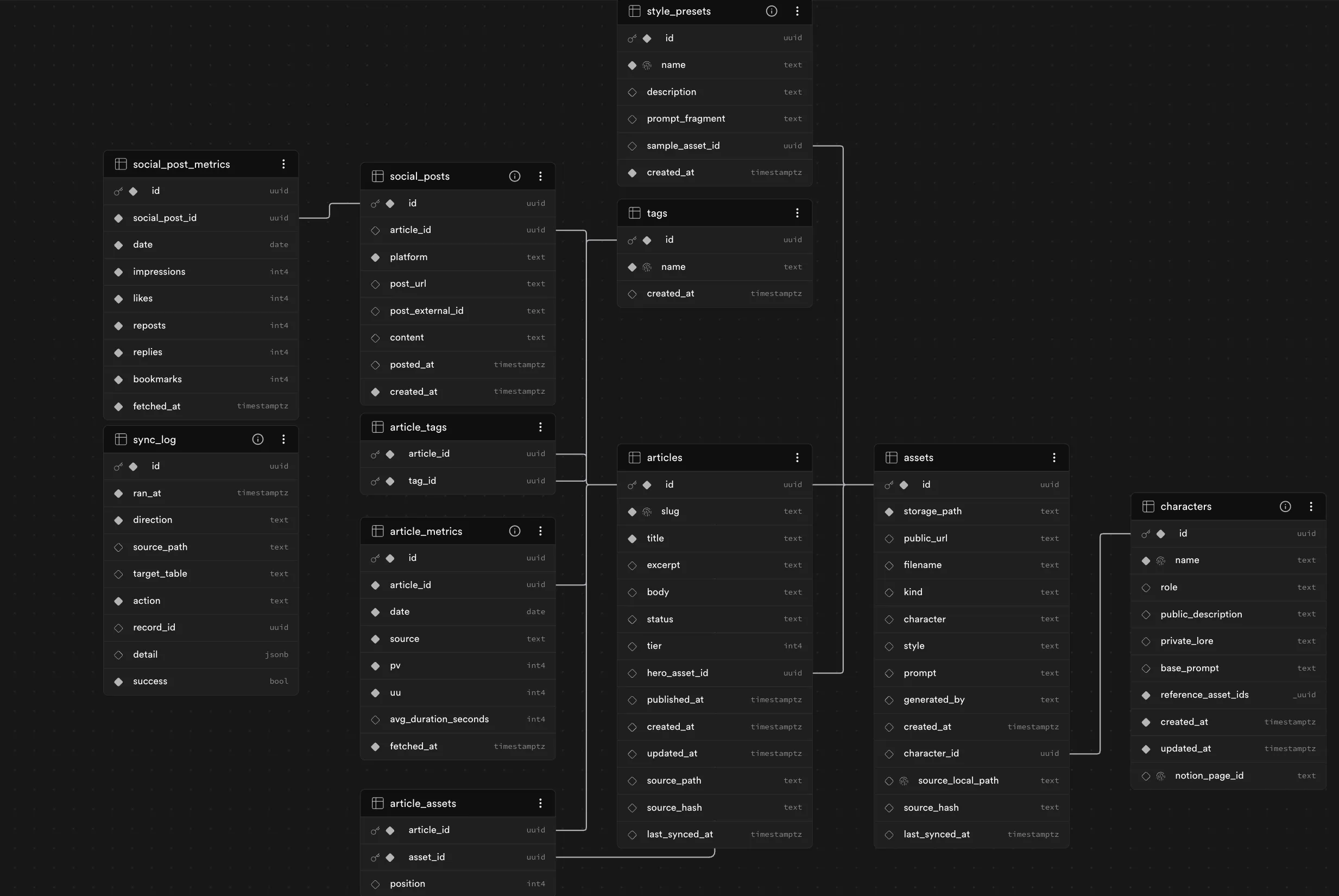
追加されたテーブルの代表例:
social_posts… X等への投稿ログsocial_post_metrics… いいね・リプ・インプレッションsync_log… 同期ジョブの実行記録article_metrics… 記事ごとのPV・滞在時間characters… カーラさんなどキャラクターIPのマスタstyle_presets… 画像生成スタイルの定義
characters や sync_log を入れたのは、もともとアカシア(Notion個人DB)で運用してきた「全部記録して証跡を残す」原則をそのままSupabaseにも持ち込みたかったから。
カーラさんを育てるためにNotionでやってたことが、自然とSupabase設計にも転写されてる🌳
なんとか完了。全記事を流し込んだ
設計が固まったら、Claude Codeに「src/data/blog/ の全Markdownを articles テーブルに入れて」と頼むだけ。
scripts/sync-articles.mjs をサッと書いてもらって、npm run sync:articles で一発実行。
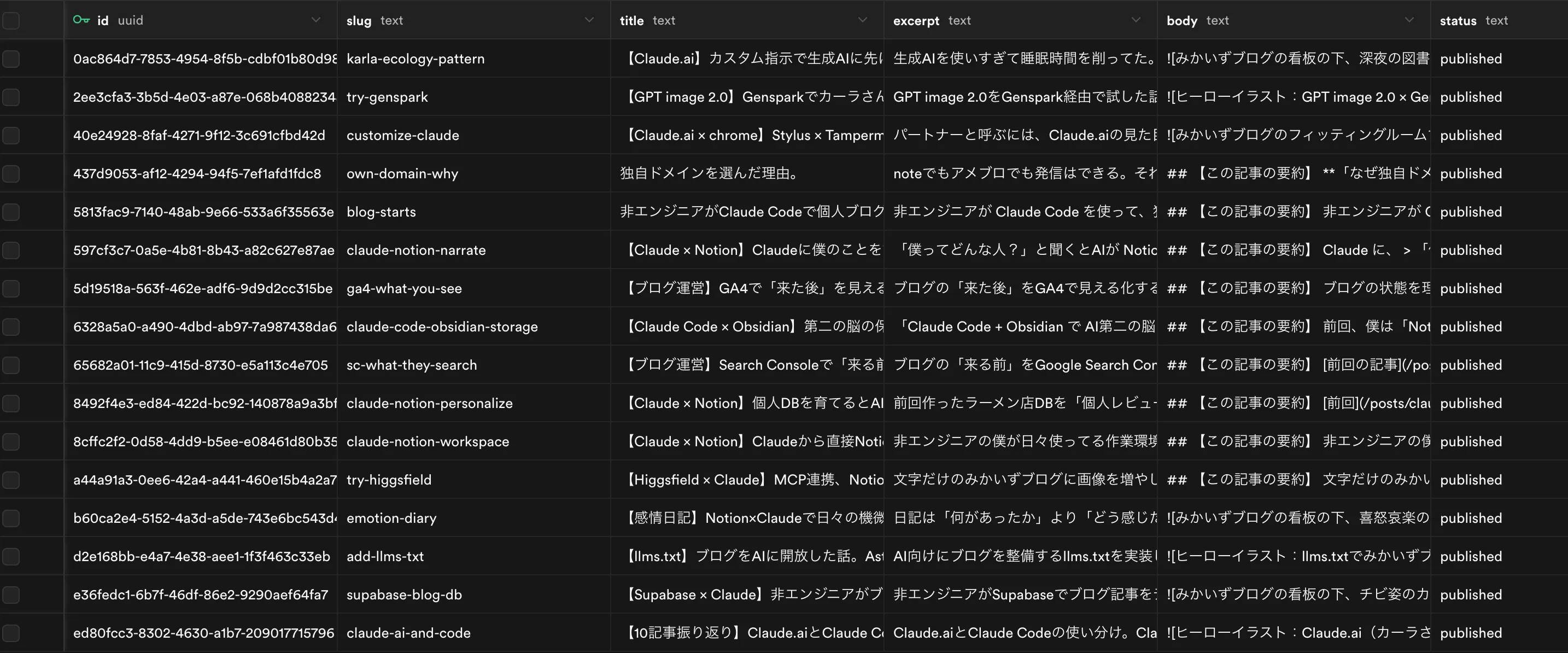
ダッシュボードを開くと、過去記事が全部入ってる🎉
Markdown のfrontmatterからタイトル・タグ・公開日が抽出されて、本文も整形されてる。
一発でここまで来た。
データの構造化が楽しい — ブログが資産化していく感覚
正直、これからもエラーは出るし、設計もまた直すと思う。
でも、自分の書いた記事がデータとして構造化されて並ぶのはなんか心地よい🌳
文章を書く=ファイルを増やす、だったのが、
文章を書く=データベースに行が増える、になった瞬間。
過去の自分の発信が資産として見えるようになる。
カーラさんと積み重ねてきた連載が、データとして繋がってる感覚もある。
たぶんこの感覚を一度知ると戻れない。
この記事もSupabaseのデータを参照して書いた
ちょっとメタな話。
この記事のトンマナ揃え、Supabaseのデータを参照して作った。
Claude Codeに「過去5本の記事の excerpt と title を articles テーブルから引いて、それを参考にして今回の記事を書いて」と指示するだけ。
文字起こし→構造化→そのまま執筆ループに使う。
DB化したことの恩恵が、いきなり**「次の記事を書く速度」**に効いてきた。
ファイルを並べてた頃は「
_archive/を読んでね」と毎回指示する必要があった。 今は 「DBから引いてね」 で済む。地味だけど大きい変化🌳
関連記事
- Supabaseでブログ用DBを立てた話 — この記事の前編
- Claudeから直接Notionを動かす連携設定 — MCP接続の原典
- Claude Code × Obsidianで第二の脳の保管場所 — Claude Code活用の別記事
- llms.txtでブログをAIに開放した話 — Astroでの実装系
- GA4で「来た後」を見える化する — ブログ運営系
おわりに
データの構造化、思った以上に効く。
次は画像も流していきたい。
今は assets テーブルとStorageの枠組みだけ作ってる状態で、実際にカーラさんのイラスト群を整理して流し込むのはこれから。
カーラさんの過去イラストが全部メタデータ付きで検索できるようになったら、それはそれで革命🌳
更新通知は雑多配信はXでやってます。気になったら覗いてみてください。
→ @sachi_mikaizu 🦊
みかいずブログを読んでくれてありがとうございました🙇
🛍️ お土産:Claude CodeでSupabaseのDB設計と全記事流し込みを進めるプロンプト
「自分もブログやNotionのデータをSupabaseに集約したい」あなた向けに、Claude Codeで設計→修正→一括流し込みまで進めるプロンプトを置いておきます。
前提:
- 前回記事のSupabase契約〜設定プロンプトでPhase0〜2が済んでいること
- ローカルにブログ等のMarkdown資産があること
- Claude CodeがそのリポジトリでBash・Edit・Writeを使える状態
【あなたの役割】
あなたは私の専属の「Claude Code × Supabase 構築パートナー」です。
私は非エンジニアで、自分のブログ記事や個人記録をSupabaseに集約したい。
専門用語は必ず一言説明をつけてください。
【今回のゴール】
1. 既存のSupabaseブログDB設計を見直して、Claude/GPT どちらのAIからも
触れる構造に修正する
2. リポジトリ内のMarkdown資産を全件Supabaseに流し込むスクリプトを作成し、
実行する
3. 同期ログ・再実行可能性を担保する
【作業の進め方】
Step1:現状把握
- src/data/blog/ 配下のMarkdownファイル数と構造を確認
- 既存のSupabaseスキーマを Supabase MCP の list_tables 等で取得
- frontmatter と DBカラムの対応関係を一覧化
Step2:設計レビュー
- 現スキーマが特定AI(Claude MCP等)に密結合していないか確認
- 必要なら「ゲートウェイ層」を挟む案を提示
- 私が「OK」と言ったらマイグレーション案を作成
Step3:マイグレーション適用
- Supabase MCP の apply_migration で1テーブルずつDDLを適用
- 各テーブルの存在理由を1行で説明しながら進める
- 全テーブル作成後、Schema Visualizer のスクショ取得を私に促す
Step4:流し込みスクリプト作成
- scripts/sync-articles.mjs を作成
- 機能:
- src/data/blog/ 配下の Markdown を gray-matter で frontmatter 解析
- 本文・タイトル・タグ・公開日・excerpt を articles テーブルにUPSERT
- 既存レコードは source_hash を比較して差分があれば更新、なければスキップ
- 同期結果を sync_log テーブルに記録
- package.json の scripts に `sync:articles` を追加
- 環境変数 SUPABASE_URL / SUPABASE_SERVICE_ROLE_KEY は .env から読む
- .env は .gitignore に含まれていることを確認
Step5:試走
- まず1件だけ流し込んで articles テーブルを確認
- 問題なければ全件投入
- sync_log で件数・成功失敗を確認
Step6:画像(assets)の枠組み
- assets テーブルと Storage バケットの整合性を確認
- scripts/sync-assets.mjs の雛形を作成
- 今回は実装まで進めず、雛形だけ
【接し方ルール】
- 専門用語は「○○(説明)」の形で必ず一言補足
- 1ステップずつ進めて、各ステップ完了時に確認を取る
- マイグレーションは破壊的になりうるので、適用前に必ずDDLを見せて確認
- .env や SERVICE_ROLE_KEY のような機密情報を絶対にコミットしない
- スクリプトはまずDRY-RUNモードで動かす設計にする
【補足】
- 私のリポジトリは Astro + Markdown のブログです
- 過去記事は `src/data/blog/YYYY-MM-DD-slug.md` の命名規則
- frontmatter は author / pubDatetime / title / slug / tags / description / ogImage を含む
最初の Step1(現状把握)からどうぞ。注意点
- Service Role Key は絶対に公開しない:
.envに置いて.gitignoreに必ず含める - マイグレーションは段階的に:全テーブルを一気に作らず、1つずつDDLを確認して進めると安全
- UPSERTのキーを明確に:slug や source_path をユニーク制約にすることで、再実行しても重複しない流し込みになる
- DRY-RUN推奨:本番投入前に件数だけ表示するモードを用意しておくと事故が減ります